COMPUTER SYSTEM ARCHITECTURE
UNIT 5
UNIT-V: Pipeline and Vector Processing: Parallel Processing. Pipelining. Arithmetic pipeline, Instruction Pipeline, RISC Pipeline, Vector Processing, Array Processors.
Text Books:
1. Computer System Architecture, M. Marris Mano, PHI 2. Computer Organization, VC Hamacher, ZG Vranesicand S.C.Zaky, McGraw Hill.
😎Please Go through the Introduction part to answer the Questions: 👉
Introduction to the Topics in Syllabus
- WHAT IS PARELLEL PROCESSING?
- Flynn’s classification.
- WHAT IS PIPELING?
INTRODUCTION:
WHAT IS PARELLEL PROCESSING?
Parallel processing is a method in computing of running two or more processors (CPUs) to handle separate parts of an overall task.
Breaking up different parts of a task among multiple processors will help reduce the amount of time to run a program.

Consider the single-processor system as the one-man company. In a one-man company the owner takes a task finishes it and further takes another task to accomplish.
If the owner has to expand his business, he has to hire more people. Hiring more people will distribute the workload and allow him to finish the jobs faster. He will also be able to increase his capacity for doing jobs. Or we can say he will able to accept more jobs than earlier. This strategy is similar to parallel processing.
REFER FIGURE BELOW, As we discussed above parallel processing breaks the task or a process into sub-tasks and distribute these sub-tasks among all the available processors present in the system. Thereby, executing the task in the shortest time.

All the processors in the parallel processing environment should run on the same operating system. All processors here are tightly coupled and are packed in one casing. All the processors in the system share the common secondary storage like the hard disk. As this is the first place where the programs are to be placed.
Flynn has classified the computer systems based on parallelism in the Instructions and in the Data streams.

Flynn’s taxonomy is a classification scheme for computer architectures proposed by Michael Flynn in 1966. The taxonomy is based on the number of instruction streams and data streams that can be processed simultaneously by a computer architecture. There are four categories in Flynn’s taxonomy:
These are:
1. Single instruction stream, single data stream (SISD).
2. Single instruction stream, multiple data stream (SIMD).
3. Multiple instruction streams, single data stream (MISD).
4. Multiple instruction stream, multiple data stream (MIMD).

figure: Unit 5 Flynn classification:
 PU: Processing Unit or CPU
PU: Processing Unit or CPU

WHAT IS PIPELING?
To improve the performance of a CPU we have two options:
1. Improve the hardware by introducing faster circuits.
2. Arrange the hardware such that more than one operation can be performed at the same time.
Since there is a limit on the speed of hardware and the cost of faster circuits is quite high, we have to adopt the 2nd option.
Pipelining is a process of arrangement of hardware elements of the CPU such that its overall performance is increased.
The pipeline is a "logical pipeline" that lets the processor perform an instruction in multiple steps.
The processing happens in a continuous, orderly, somewhat overlapped manner.
Design of a basic pipeline
- In a pipelined processor, a pipeline has two ends, the input end and the output end. Between these ends, there are multiple stages/segments such that the output of one stage is connected to the input of the next stage and each stage performs a specific operation.
- Interface registers are used to hold the intermediate output between two stages. These interface registers are also called latch or buffer.
- All the stages in the pipeline along with the interface registers are controlled by a common clock.
A useful method of demonstrating this is the laundry analogy. Let's say that there are four loads of dirty laundry that need to be washed, dried, and folded. We could put the the first load in the washer for 30 minutes, dry it for 40 minutes, and then take 20 minutes to fold the clothes. Then pick up the second load and wash, dry, and fold, and repeat for the third and fourth loads. Supposing we started at 6 PM and worked as efficiently as possible, we would still be doing laundry until midnight.


- Non-Pipelined Execution
- Pipelined Execution
For example, consider a processor having 5 stages and let there be 5 instructions to be executed.
We can visualize the execution sequence through the following space-time diagrams.
1. Non-Pipelined Execution (Non-overlapped execution)-
In non-pipelined architecture,
- All the instructions of a program are executed sequentially one after the other.
- A new instruction executes only after the previous instruction has executed completely.
- This style of executing the instructions is highly inefficient.
Execution sequence of instructions in a processor can be visualized using a space-time diagram.

Execution in a pipelined processor
Pipeline Stages :
Pipelining organizes the execution of the multiple instructions simultaneously.
In pipelining the instruction is divided into the subtasks. Each subtask performs the dedicated task.
Look at the figure below the 5 instructions are pipelined.
The instruction is divided into 5 subtasks: instruction fetch, instruction decode, operand fetch, instruction execution and operand store.
(In some book it is
5 stage pipeline:Fetch – Decode – Read – Execute - Write)
- In the first subtask, the instruction is fetched.
- The fetched instruction is decoded in the second stage.
- In the third stage, the operands of the instruction are fetched.
- In the fourth, arithmetic and logical operation are performed on the operands to execute the instruction.
- In the fifth stage, the result is stored in memory.
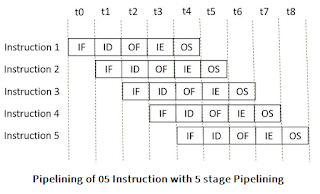 Observe that when the Instruction fetch operation of the first instruction is completed in the next clock cycle the instruction fetch of second instruction gets started. This way the hardware never sits idle it is always busy in performing some or other operation. But, no two instructions can execute their same stage at the same clock cycle.
Observe that when the Instruction fetch operation of the first instruction is completed in the next clock cycle the instruction fetch of second instruction gets started. This way the hardware never sits idle it is always busy in performing some or other operation. But, no two instructions can execute their same stage at the same clock cycle.

Types of Pipelining
In 1977 Handler and Ramamoorthy classified pipeline processors depending on their functionality.
1. Arithmetic Pipelining (Also refer Question # 07 in the end of this Page)
It is designed to perform high-speed floating-point addition, multiplication and division. Here, the multiple arithmetic logic units are built in the system to perform the parallel arithmetic computation in various data format. Examples of the arithmetic pipelined processor are Star-100, TI-ASC, Cray-1, Cyber-205.
2. Instruction Pipelining (Also refer Question # 05 in the end of this Page)
Here, the number of instruction are pipelined and the execution of current instruction is overlapped by the execution of the subsequent instruction. It is also called instruction lookahead.
3. Processor Pipelining
4. Uni function Vs. Multifunction Pipelining
5. Static vs Dynamic Pipelining
6. Scalar vs Vector Pipelining:
Scalar pipelining processes the instructions with scalar operands. The vector pipeline processes the instruction with vector operands.********************************************************************************************
👱 Asked in Previous year University Papers (COMPILED FROM UNIVERSITY QUESTION PAPERS)
1. What do you understand by parallel processing? Describe Flynn's classification of parallel processing.
Ans:
Click for the Detailed Solution 👉 Flynn's Classification- 4 category
OR
Short Answer:
Prerequisite: Also see Notes Above in Flynn's section (above 👆 top of page).
Flynn's Classification of Computers
M.J. Flynn proposed a classification for the organization of a computer system by the number of instructions and data items that are manipulated simultaneously.
The sequence of instructions read from memory constitutes an instruction stream.
The operations performed on the data in the processor constitute a data stream.
Flynn's classification divides computers into four major groups that are:
- Single instruction stream, single data stream (SISD)
- Single instruction stream, multiple data stream (SIMD)
- Multiple instruction stream, single data stream (MISD)
- Multiple instruction stream, multiple data stream (MIMD)
.jpeg)
2. What is the use of pipelining?
Prove that an M- stage linear pipeline can be at most M times faster than that of non-pipelined serial processor.
Ans: Click for the Detailed Solution 👉M Stage Solution
OR
Short Answer:
Consider a ‘M’ segment pipeline with clock cycle time as ‘Tp’.
Let there be ‘n’ tasks to be completed in the pipelined processor.
Now, the first instruction is going to take ‘M’ cycles to come out of the pipeline but the other ‘n – 1’ instructions will take only ‘1’ cycle each, i.e, a total of ‘n – 1’ cycles.
Each Cycle = Tp
So, time taken to execute ‘n’ instructions in a pipelined processor:
= (M)Tp + (n – 1) Tp = [M + (n – 1)] Tp ------------(1)
In the same case, for a non-pipelined processor, the execution time of ‘n’ instructions will be: ETnon-pipeline = n * M * Tp------------(2)
So, speedup (S) of the pipelined processor over the non-pipelined processor, when ‘n’ tasks are executed on the same processor is:
S = Performance of non-pipelined processor / Performance of pipelined processorAs the performance of a processor is inversely proportional to the execution time, we have,
S = ETnon-pipeline / ETpipeline =(1)/(2) => S = [n * M * Tp] / [(M + n – 1) * Tp] S = [n * M] / [M + n – 1]When the number of tasks ‘n’ is significantly larger than k, that is, n >> k
S = n * M / n S = Mwhere ‘M’ are the number of stages in the pipeline
3. Specify a pipeline configuration to carry out Arithmetic Operation (Ai*Bi) + Ci
Ans:
Click for the Detailed Solution 👉Ai*Bi +Ci
4. Specify a pipeline configuration to carry out Arithmetic Operation (Ai+Bi)*(Ci+Di).
Ans: Click for the Detailed Solution 👉 (Ai+Bi )* (Ci+Di)
5. Draw and explain flow chart and timing diagram for the four segment instruction pipeline.
Ans: Click for the Detailed Solution 👉4 Stage pipeline
OR
Short Answer:
In general, the computer needs to process each instruction with the following sequence of steps.
- Fetch instruction from memory.
- Decode the instruction.
- Calculate the effective address.
- Fetch the operands from memory.
- Execute the instruction.
- Store the result in the proper place.
Each step is executed in a particular segment.
- Example: four segment instruction pipeline
Flow chart: Figure | Four Segment Instruction Pipeline

The above figure shows operation of 4-segment instruction pipeline. The four segments are represented as- FI: segment 1 that fetches the instruction.
- DA: segment 2 that decodes the instruction and calculates the effective address.
- FO: segment 3 that fetches the operands.
- EX: segment 4 that executes the instruction
- FI: segment 1 that fetches the instruction.
- DA: segment 2 that decodes the instruction and calculates the effective address.
- FO: segment 3 that fetches the operands.
- EX: segment 4 that executes the instruction
Timing diagram:
The space time diagram for the 4-segment instruction pipeline is given below:

6. Write short notes on
(i) Vector processor
(ii) Array processor
Ans:
Computer Architecture- Advanced Architectures - SIMD Architectures
Data parallelism: executing one operation on multiple data streams
-Concurrency in time – vector processing
-Concurrency in space – array processing
OR
Data parallelism in time = vector processing
Data parallelism in space = array processing
(i) Vector processor: Click for the Detailed Solution 👉 vector processor
- Computers having vector instruction are vector processors.

- Vector processor have the vector instructions which operates on the large array of integer or floating-point numbers or logical values or characters, all elements in parallel. It is called vectorization.
- Vectorization is possible only if the operation performed in parallel are independent of each other.
- Operands of vector instruction are stored in the vector register. A vector register stores several data elements at a time which is called vector operand.
- A vector operand has several scalar data elements.
- A vector instruction needs to perform the same operation on the different data set. Hence, vector processors have a pipelined structure.
- Vector processing ignores the overhead caused due to the loops while operating on an array.

So, this is how vector processing allows parallel operation on the large arrays and fasten the processing speed.
(ii) Array processor
Ans: (i) Array processor: Click for the Detailed Solution 👉 Array Processor
Types of Array Processor
There are two types of array processor like; attached and SIMD , See Detailed Notes.
7. What is Arithmetic pipeline. Explain Floating Point addition (using arithmetic pipeline) .
Ans: Arithmetic Pipeline :
An arithmetic pipeline divides an arithmetic problem into various sub problems for execution in various pipeline segments. It is used for floating point operations, multiplication and various other computations. The process or flowchart arithmetic pipeline for floating point addition is shown in the diagram.
Floating point addition using arithmetic pipeline :
The following sub operations are performed in this case:
- Compare the exponents.
- Align the mantissas.
- Add or subtract the mantissas.
- Normalize the result
First of all the two exponents are compared and the larger of two exponents is chosen as the result exponent. The difference in the exponents then decides how many times we must shift the smaller exponent to the right. Then after shifting of exponent, both the mantissas get aligned. Finally the addition of both numbers take place followed by normalization of the result in the last segment.
Example:
Let us consider two numbers,
X=0.3214*10^3 and Y=0.4500*10^2
Explanation:
First of all the two exponents are subtracted to give 3-2=1. Thus 3 becomes the exponent of result and the smaller exponent is shifted 1 times to the right to give
Y=0.0450*10^3
Finally the two numbers are added to produce
Z=0.3664*10^3
As the result is already normalized the result remains the same.
*****************************************************************************
Above SOLUTION prepared for LAST MOMENT PREPARARTIONS.
Thank you
Pradeep Kumar
Educational Purpose Only: The information provided on this blog is for general informational and educational purposes only. All content, including text, graphics, images, and other material contained on this blog, is intended to be a resource for learning and should not be considered as professional advice.
No Professional Advice: The content on this blog does not constitute professional advice, and you should not rely on it as a substitute for professional consultation, diagnosis, or treatment. Always seek the advice of a qualified professional with any questions you may have regarding a specific issue.
Accuracy of Information: While I strive to provide accurate and up-to-date information, I make no representations or warranties of any kind, express or implied, about the completeness, accuracy, reliability, suitability, or availability with respect to the blog or the information, products, services, or related graphics contained on the blog for any purpose. Any reliance you place on such information is therefore strictly at your own risk.
External Links: This blog may contain links to external websites that are not provided or maintained by or in any way affiliated with me. Please note that I do not guarantee the accuracy, relevance, timeliness, or completeness of any information on these external websites.
Personal Responsibility: Readers of this blog are encouraged to do their own research and consult with a professional before making any decisions based on the information provided. I am not responsible for any loss, injury, or damage that may result from the use of the information contained on this blog.
Contact: If you have any questions or concerns regarding this disclaimer, please feel free to contact me at my email: pradeep14335@gmail.com
Nice post www,englishinbhilai.com
ReplyDelete